2019: Week 7 Solution
Hello everyone! So far it has been me (Carl) setting the challenges with Jonathan writing the solution posts. This week, roles have been reversed as I sneaked away to Thailand for a couple if weeks so thanks to Jonathan for keeping the (cargo) ship afloat whilst I have been away.
Writing the challenge post requires Jonathan or I to have no idea about the challenge or how to approach it so was really pleased to see a challenge that has a lot of different of ways to resolve it. I will try to show a few thoughts about approaches at a couple of key points throughout the solution.
For me, I prefer to use left, right and mid as functions to break down strings in to sub-strings. For the 'Departure Date' calculation, I simply used right() as all days in the ID field has double digits:
 For the 'Ship ID' a little more care was needed as not all the Ships had the same length name (you couldn't make this stuff up could you?!). To resolve this challenge, I used find() but what we want to return is everything before the second hyphen. Therefore, it's not find() we want to use but findnth(). This is a super useful function and has saved me from using regex many times.
For the 'Ship ID' a little more care was needed as not all the Ships had the same length name (you couldn't make this stuff up could you?!). To resolve this challenge, I used find() but what we want to return is everything before the second hyphen. Therefore, it's not find() we want to use but findnth(). This is a super useful function and has saved me from using regex many times.



Thanks to all of those that took part and submitted that they completed the challenge on the Google Form.
Writing the challenge post requires Jonathan or I to have no idea about the challenge or how to approach it so was really pleased to see a challenge that has a lot of different of ways to resolve it. I will try to show a few thoughts about approaches at a couple of key points throughout the solution.
The join calculation
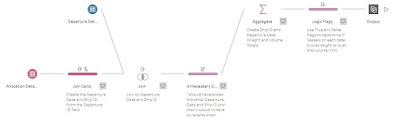
In what has become a classic Preppin' Data move already, we needed to create a calculation that broke down the 'Departure ID'. I'm not sure who coded that as an ID field as they were shortly let go from Chin & Beard Suds Co after that idea. What is needed for the join is to have both the 'Departure Date' and 'Ship ID' as if not, days with multiple ships sailing or ships used repeatedly, would create multiple records when there was actually on one sailing by that ship, on that day.For me, I prefer to use left, right and mid as functions to break down strings in to sub-strings. For the 'Departure Date' calculation, I simply used right() as all days in the ID field has double digits:

Aggregation
The next challenge the data had was to pull together the total volume and total weight. I did this in the only way to aggregate rows together in Prep which is with the Aggregation step.
Here I originally thought I needed to aggregate just the total weight and volume for each Ship ID and Departure Date. By doing this though, Prep removes all of the max weights and volumes which I need for the next calculations. Therefore, I feel like I cheated a little by choosing the average max weight and volume for each Ship ID and Departure Date. This enabled these metrics to all be carried through, rather than me having to do a join to an earlier part of the flow to get the missing columns.
Over-max flags
The final piece of the proverbial jigsaw was to create indicators, or flags, that would show when there was too much volume or weight of cargo allocated to a certain vessel, on a certain day. I went with a simple boolean calculation that took my aggregated totals (formed above) and simply tested to see if this value was larger than the max weight or volume number for the respective measure. ie

The result of this calculation is either 'True' if the weight exceeds the max weight or 'False' if it doesn't. These style calculations are very useful in lots of use cases including logistics examples like this as a quick indicator as to whether the issue warrants further review.
Here's my final solution (click on the image to download the file):
Alternative Solutions
There are some other solutions possible too. Some of my favourites were:
- Concatenate the Ship ID and Departure in to a single field to join on
- For those regex lovers, using Regex to break up the Departure ID
Thanks to all of those that took part and submitted that they completed the challenge on the Google Form.


