How to...Handle Free Text
Free isn't always a good thing. In data, Free text is the example to state when proving that statements correct. However, lots of benefit can be gained from understanding data that has been entered in Free Text fields.
Split and Pivot

What do we mean by Free Text?
Free Text is the string based data that comes from allowing people to type answers in to systems and forms. The resulting data is normally stored within one column, with one answer per cell. As Free Text means the answer could be anything, this is what you get - absolutely anything. From expletives to slang, the words you will find in the data may be a challenge to interpret but the text is the closest way to collect the voice of your customer / employee.
The Free Text field is likely to contain long, rambling sentences that can simply be analysed. If you count these fields, you are likely to have one of each entry each. Therefore, simply counting the entries will not provide anything meaningful to your analysis. The value is in the individual words / ID numbers within those sentences and paragraphs submitted.
Why is Free Text useful?
Capturing simple survey results as the percentage isn't that useful in informing you where your business could improve. Hearing the "voice" of your customer in their own words will tell you more than even the best analysts in the world would be likely to. This is where Free Text entry on forms come in.
The flexibility to capture anything the user of the form wants to share can make the data extremely useful. Sadly, it also makes the data harder to analyse. This led to a split in analysis of this kind:
- Free Text - organisations would often give Third Party companies or junior employees the task of reading each comment and 'categorising' it. This actually restricts the value of the comment made as you should have forced a choice from the user in the first place.
- No Free Text - paying for Third Parties to conduct this work is expensive. Therefore, lots of organisations removed the Free Text entry to lock down the responses to make it easier to measure the responses in their analysis. This obviously removes the flexibility for the user of the form to share their valuable insights.
Free Text often fills the gaps in poor, or developing, systems. Organisations struggle with key Operational System changes as either the complexity of the system or cost to make the changes is too significant. Free Text allows the data that needs to be captured to make the system functional be captured and stored. Just from a data analysis perspective, this becomes difficult to analyse on a large scale.
What approach should be used to analyse Free Text in Tableau?
Free Text is extremely valuable and shouldn't be eradicated from forms and systems. Free Text allows for a 'catch all' bucket response when the rest of your system or form doesn't allow the user to give the information in any way. Writing unbiased surveys is a very difficult skill to develop so a Free Text box can capture information that wouldn't be gathered otherwise. This might lead to product innovations or highlight service gaps you wouldn't find without more costly customer interviews.
To find these nuggets of information is not straight forward. As mentioned above for the following reasons:
To find these nuggets of information is not straight forward. As mentioned above for the following reasons:
- Each response is likely to be unique is you get more than four words from a respondent.
- Finding a particular word is easy through a Contains() function but you need to know what to look for. The whole point of Free Text is that your users might be telling you something that you don't know.
- There will be lots of words you need to get rid of, doing this can take a lot of work.
Therefore, the steps you need to take to analyse Free Text is:
- Split sentences in to multiple columns so each word is held separately (this can create a very wide data set)
- Pivot these columns in to a single column to make cleaning a lot easier
- Remove punctuation, spaces, hashtags, change case to all be the same (recommendation make all letter case lower case).
- Join a data set of common words (ie. the, or, they etc) as they will not add any value in your analysis and remove any words that are in both data sets. These list of most common words are easily available through a Google search.
- Add in the original full free text if removed throughout the flow so context can be given to the word in your final analysis.
How can Prep help?
There are four steps Prep can be used for that will make analysing Free Text easier are:
Split and Pivot

Breaking apart the longer strings into individual words is a key step when working with Free Text. The 'Automatic Split' option within Prep will often do the hard work for you by finding the common separator within the text field and each time that 'separator' is found, Prep will create a new column.

The new columns will have the same name as the existing field's name but will add a '- Split nn' on the end for each new split result. For example in the example above, there are 28 spaces in the longest 'Notes' field and therefore 29 new fields are created to make sure all words are returned.
As can be seen above, there are a number of Blank values returned for the records that do not have that large number of the space separator. Therefore, pivoting has two purposes:

With potentially tens, if not hundreds of columns to pivot, dragging each in to the pivot tool can take a long time. The Prep team have thought above this and the 'wildcard search to pivot' helps to make this process a lot easier and also future-proofs the flow incase updated data actually has longer sentences in the Free Text field.

The wildcard search should not use the original field name (unless you have split multiple fields) as you want just the separated words. After this step it's very easy to remove the nulls from the dataset. See the 'How to...' post on filtering for more details.


The new columns will have the same name as the existing field's name but will add a '- Split nn' on the end for each new split result. For example in the example above, there are 28 spaces in the longest 'Notes' field and therefore 29 new fields are created to make sure all words are returned.
As can be seen above, there are a number of Blank values returned for the records that do not have that large number of the space separator. Therefore, pivoting has two purposes:
- Putting all the words in one column so cleaning operations described in step 3 above.
- Removing blank rows to reduce the dataset (often considerably) and improving the processing time for the rest of your data preparation flow.

With potentially tens, if not hundreds of columns to pivot, dragging each in to the pivot tool can take a long time. The Prep team have thought above this and the 'wildcard search to pivot' helps to make this process a lot easier and also future-proofs the flow incase updated data actually has longer sentences in the Free Text field.

The wildcard search should not use the original field name (unless you have split multiple fields) as you want just the separated words. After this step it's very easy to remove the nulls from the dataset. See the 'How to...' post on filtering for more details.

Clean Cases and Punctuation
Table Desktop is can be case sensitive depending on the source of the data when counting string based data. Therefore String and string would not always be counted as two records of the same value. Prep has a range of options to help make sure you can match as many values as possible through just a few clicks.

Getting rid of unnecessary punctuation is just as important as matching cases. 'String.' is not the same as 'String' so removing any spaces or punctuation will allow you to develop the best analysis possible.
Remove Common Words
Getting rid of unnecessary punctuation is just as important as matching cases. 'String.' is not the same as 'String' so removing any spaces or punctuation will allow you to develop the best analysis possible.
The results are already useful but to save a lot of time sifting through a lot of words that won't add much insight, a useful step is to remove the most common words in the language used run the Free Text field. For the Week 5 2019 challenge example, five of the top ten common words would give us no insight at all: to, the, about, gave, a.

To remove these common words, finding a list of common words via Google is an easy thing to do. Having a list as a data source allows you to bespoke the words you want to remove over time. Here's the data source that forms the basis for this type of analysis for me.

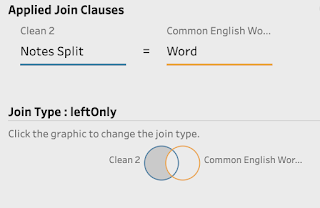
The Join set-up is important to ensure common words are removed. By joining the word from the list of common words, to the single word you have broken out of your Free Text field, you can then remove any that 'Join', ie. any that are found in both lists. To do this, click on the intersecting part of the Join condition to leave the join set-up looking like the below image.



Clean through Grouping
The last stage will have to be optional and is based on the analysts opinion. If you group values that shouldn't be, you will get answers to questions that are not true. Vice versa, if you have similar values that can be grouped and aren't, you are going to struggle to find the signal in the noise. Prep has a great range of options to help you group flexibly as well through just a couple of clicks. Some of the grouping algorithms can be made more, or less, sensitive to make the results more fitting of the requirement.

There's more detail on grouping in the 'How to... Clean by Grouping' post.
Using Free Text to provide insight in to your customers opinions / feedback can add much more value than hours of number crunching so mastering the above technique can be a big timesaver and support the development of your analysis.
________________________________________________________________
To practice the techniques cover above, try the following weekly challenges:
The last stage will have to be optional and is based on the analysts opinion. If you group values that shouldn't be, you will get answers to questions that are not true. Vice versa, if you have similar values that can be grouped and aren't, you are going to struggle to find the signal in the noise. Prep has a great range of options to help you group flexibly as well through just a couple of clicks. Some of the grouping algorithms can be made more, or less, sensitive to make the results more fitting of the requirement.

Using Free Text to provide insight in to your customers opinions / feedback can add much more value than hours of number crunching so mastering the above technique can be a big timesaver and support the development of your analysis.
________________________________________________________________
To practice the techniques cover above, try the following weekly challenges:

