2023: Week 17 - Population Growth vs Country Size
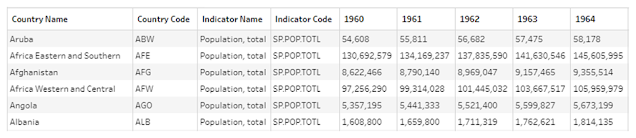
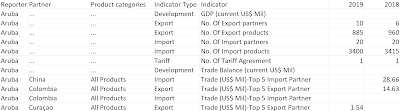
Challenge by: Serena Purslow We have a guest contributor this week! Serena is from DS36 at the Data School and passionate about working with Environmental, Social and Governance (ESG) data. This challenge uses data directly from the world bank, but it’s a bit of a mess! The goal is to calculate the change in population per km 2 across the world, to find which countries have seen the biggest increase over the past 21 years. Inputs World Population Data 1960 - 2021 Country Size Data Requirements Input the data Population data: Use the data interpreter to ensure the headers are read as headers Remove unnecessary fields Trim leading & trailing spaces from country names Use the Country/Region data role to tidy up country names Pivot data so we have 3 columns for year, population and country name Country size data: Split the Land in km2 (mi2) field to get the values for land size in km 2 only Remove unnecessary fields - we only want country and l...