2019: Week 32 Solution

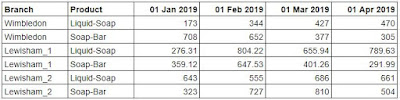
You can view our full solution workflow below and download it here ! Our full solution workflow. 1. Pivot the products and associated sales. The first step in our workflow is to convert the [Product 1] & [Product 2] fields and the [Sales] & [Sales 1] fields into two fields, [Product] & [Sales], so we have one product and one sales value per row. To do this, we can use a column to rows pivot. First add the two product fields to Pivot1 Values. Then, add a second set of pivot values using the ‘+’ icon underneath the pivot type drop down. Finally, add the two sales fields to the Pivot2 Values area. Take care to align [Sales] with [Product 1] and [Sales 1] with [Product 2] as this ensures they are on the correct rows together Pivoting the Products & Sales into their correct rows. 2. Remove the dashes from the product names. Either in a clean step or in the pivot step we just used, update the new [Product] field by creating a new calculated field with the...