2019: Week 9 Solution
First let me preface this write-up by stating that these complaints make up the minority of our feedback – most of our customers are incredibly happy with our products and we have won all lawsuits against us. Not that any lawsuits occurred. But if they did, we won them.
This week I’ll once again be covering some of the main challenges faced and techniques used to overcome them. You can view our whole dynamic solution below and download it here (you can also find a less dynamic but also viable solution there too!).


However, this only applies when you’re using the split on an untouched field from your data source. If you create a calculated field that changes the original data then you’ll suddenly find that after the 10th split your Tableau Prep suddenly starts spitting out nasty Java.Lang.RuntimeException errors, boo!

This is unfortunate as there were a couple of data cleaning steps that it would have been nice to do before pivoting all the words in each Tweet. There are a couple of ways around this, including splitting each Tweet into chunks containing 10 or less spaces but none of these are pretty and I think most people including myself decided it’d be better to split first and clean later.


One option is, at the very start, manually add a space between “soap…” and “I”. This still lets you split using All and doesn’t lose “I” as a word. Another option is to simply manually replace “soapI” with “soap”; looking at the 250 most common words confirms that “I” is one of them, so it won’t be in the output anyway. However, this isn’t very dynamic and Carl did mention that “We need… be ready to re-run this analysis at any time. In the future someone might accidentally produce other conjoined words using a special character and we wouldn’t catch it until we spot “blitheringidiots” as a single word when it should have been two different ones.
The dynamic way I came up with to handle this situation is as follows:
1. Split each [Tweet] on every space as normal. Pivot these to create the field of all words which I called [Words Raw]. Then remove all rows containing the @C&BSudsCo twitter handle and any row with an empty word.
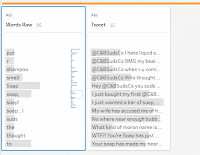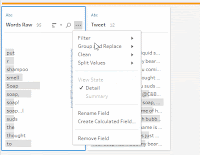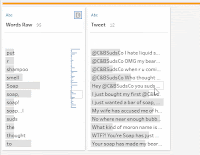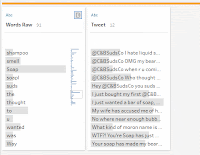
2. Create a calculated field called [Words Cleaner]. This calculated field contains the following formula:
This formula looks for any single character [], that’s not ^ one of the following: an alphanumeric character (letters, numbers, or underscores) \w, a white-space character (spaces) \s, a straight apostrophe ', a curved apostrophe ’, or a hyphen -. Any character that matches these criteria is then replaced with a space.
This essentially converts all special characters into spaces APART from apostrophes and hyphens (which can occur in the middle of a valid word, such as “don’t” or “on-site”) into a space.
In our case, this is so that can separate incorrectly conjoined words, such as “soap…I” without converting “you've” into “you ve” and “I’m” into “I m”.

3. Then use the Clean > Remove Punctuation option to remove all remaining punctuation as well as the Clean > Trim Spaces and Clean > Remove Extra Spaces.
In our case this means we’ve successfully converted “soap…I” into “soap I” whilst also still successfully converting “you've” into “youve” and “I’m” into “Im”.

4. Now we can split [Words Raw] on each space. Most of our words will be in [Words Raw – Split 1], however any words that were conjoined will end up in [Words Raw – Split 2]. If someone typed.like.this then we’d get a 3rd column too.
In our case, [Words Raw – Split 2] should contain 145 rows that are empty and one row that contains the word “I”.

5. Finally, we can use another wildcard columns-to-rows pivot to combine all our split columns back into a single field called [Words]. Filtering out the empty [Words] leaves us successfully and dynamically having recovered all words into a single field.


A left-outer join only returns rows from the left data set that do not match with any row from the right data set. In Tableau Prep the join clause isn’t case sensitive, so we don’t need to make all of our data uppercase or lowercase to make the join work. However that doesn’t mean we don’t need to do any preparation for the join.
Many of you, including myself, removed all punctuation from the Complaints data before this join. However, the CEW data does include punctuation in the form of the word “don’t”. None of our complaints Tweets include the word “don’t”, but future complaints might! For this reason, before we join our complaints [Words] to the CEW [Words] we need to use Clean > Remove All Punctuation on [Words].
This week I’ll once again be covering some of the main challenges faced and techniques used to overcome them. You can view our whole dynamic solution below and download it here (you can also find a less dynamic but also viable solution there too!).

The Bug
One of the main issues involved in this week’s challenge was finding away around a known Tableau Prep bug. As of 2019.1.3, the “All” option in Automatic Split and Custom Split allows you to split a text field on every instance of your chosen delimiter. No more capping at splitting off the first or last 10, hooray!
However, this only applies when you’re using the split on an untouched field from your data source. If you create a calculated field that changes the original data then you’ll suddenly find that after the 10th split your Tableau Prep suddenly starts spitting out nasty Java.Lang.RuntimeException errors, boo!

This is unfortunate as there were a couple of data cleaning steps that it would have been nice to do before pivoting all the words in each Tweet. There are a couple of ways around this, including splitting each Tweet into chunks containing 10 or less spaces but none of these are pretty and I think most people including myself decided it’d be better to split first and clean later.
Get each word into a single column
As mentioned above, you can now use the All option when splitting a field. This means in our data you can split each [Tweet] on every space to produce 21 new fields called [Tweet – Split 1] to [Tweet – Split 21]. In order to now get these into a single column we can insert a Pivot step set to Columns to Rows. We can then make our lives even more dynamic by opting to use a wildcard pivot (opposed to dragging and dropping all fields in) where we pivot every field contained “Split”. This now gives us all our words in a nice neat field, which I have called [Words Raw] (due to the fact there’s still some clean-up required).
Removing punctuation
After we’ve got our words into a column, and perhaps performed some other clean-up such as removing our Twitter handle and any empty rows, we now need to remove pesky punctuation that’s kicking around. The quickest way to do this is using the Clean > Remove Punctuation option. All punctuation has now been removed – problem solved! Or is it…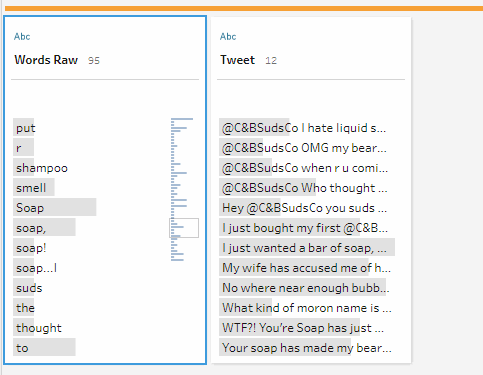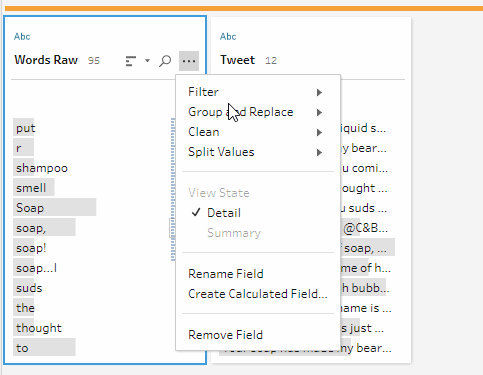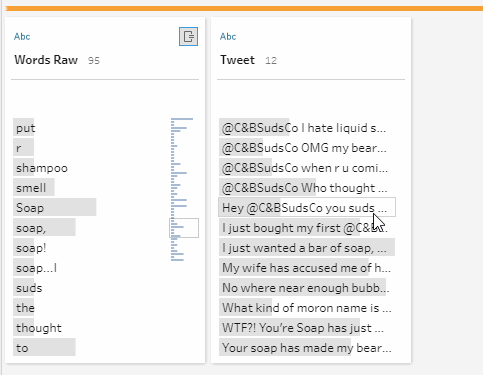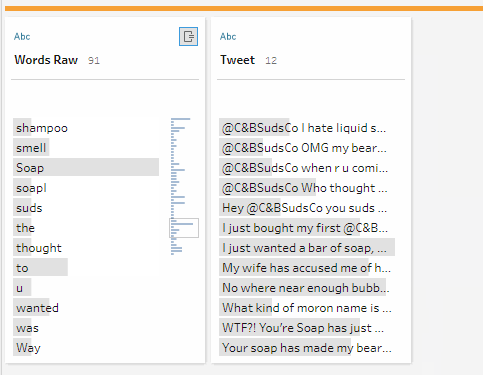
Solving the “soapI” problem
As a few of you pointed out, one of the tweets contain the phrase “you suds are soap…I expected beer!”. If you split this into words based on spaces, this produces the word “soap…I”. Removing punctuation then produces “soapI”. I don’t think we really want to count “soapI” as a word if we can help it.
One option is, at the very start, manually add a space between “soap…” and “I”. This still lets you split using All and doesn’t lose “I” as a word. Another option is to simply manually replace “soapI” with “soap”; looking at the 250 most common words confirms that “I” is one of them, so it won’t be in the output anyway. However, this isn’t very dynamic and Carl did mention that “We need… be ready to re-run this analysis at any time. In the future someone might accidentally produce other conjoined words using a special character and we wouldn’t catch it until we spot “blitheringidiots” as a single word when it should have been two different ones.
The dynamic way I came up with to handle this situation is as follows:
1. Split each [Tweet] on every space as normal. Pivot these to create the field of all words which I called [Words Raw]. Then remove all rows containing the @C&BSudsCo twitter handle and any row with an empty word.
2. Create a calculated field called [Words Cleaner]. This calculated field contains the following formula:
REGEXP_REPLACE( [Words Raw], "[^\w\s'’-]", " ")
This formula looks for any single character [], that’s not ^ one of the following: an alphanumeric character (letters, numbers, or underscores) \w, a white-space character (spaces) \s, a straight apostrophe ', a curved apostrophe ’, or a hyphen -. Any character that matches these criteria is then replaced with a space.
This essentially converts all special characters into spaces APART from apostrophes and hyphens (which can occur in the middle of a valid word, such as “don’t” or “on-site”) into a space.
In our case, this is so that can separate incorrectly conjoined words, such as “soap…I” without converting “you've” into “you ve” and “I’m” into “I m”.

3. Then use the Clean > Remove Punctuation option to remove all remaining punctuation as well as the Clean > Trim Spaces and Clean > Remove Extra Spaces.
In our case this means we’ve successfully converted “soap…I” into “soap I” whilst also still successfully converting “you've” into “youve” and “I’m” into “Im”.

4. Now we can split [Words Raw] on each space. Most of our words will be in [Words Raw – Split 1], however any words that were conjoined will end up in [Words Raw – Split 2]. If someone typed.like.this then we’d get a 3rd column too.
In our case, [Words Raw – Split 2] should contain 145 rows that are empty and one row that contains the word “I”.

5. Finally, we can use another wildcard columns-to-rows pivot to combine all our split columns back into a single field called [Words]. Filtering out the empty [Words] leaves us successfully and dynamically having recovered all words into a single field.

Filtering out the 250 most common words
The last challenge is to filter out any words that are considered absurdly common as defined in the Common English Words (CEW) data. The best way of achieving this is using a Left-Outer join between the Complaints data (on the left) and the CEW data (on the right) on [Words] = [Word]. You can create a left-outer join by clicking on the Venn-diagram in the Join Settings.
A left-outer join only returns rows from the left data set that do not match with any row from the right data set. In Tableau Prep the join clause isn’t case sensitive, so we don’t need to make all of our data uppercase or lowercase to make the join work. However that doesn’t mean we don’t need to do any preparation for the join.
Many of you, including myself, removed all punctuation from the Complaints data before this join. However, the CEW data does include punctuation in the form of the word “don’t”. None of our complaints Tweets include the word “don’t”, but future complaints might! For this reason, before we join our complaints [Words] to the CEW [Words] we need to use Clean > Remove All Punctuation on [Words].


