2022: Week 10 - Solution

This week's challenge was celebrating International Women's Day by looking at the Bechdel Test. This looks at the interactions between women in films and if those conversations were relating to something other than a man!
Step 1 - Parse Download Data Table
First we want to focus on the Webscraping table, and split out each of the fields containing a movie title.
To do this we want to split the Download Data field using a custom split on '>'.

This creates around 57 extra fields, but we can remove the majority of them so that we are left with the fields:
- DownloadData Split 2 - (Movie Title)
- DownloadData Split 5 - (Test Pass/Fail)
- Year

Then finally we can clean the Movie title field with the following calculations:
Movie
REPLACE([DownloadData - Split 5],'</a',"")
Movie
REPLACE([Movie],'&','&')
Then we can remove the DownloadData Split 2 field so we are left with the following:

Step 2 - Clean HTML
As a result of the webscraping, it looks like there are still some movie titles with HTML elements in them.
First we need to clean the HTML table so that it is in a shape that we can join it to the movie titles.
1. Update the Char 'space' with the following calculation:
Char
IF CONTAINS([Description],'space')
THEN ' '
ELSE [Char]
END
We can then pivot the data using a Columns to Rows pivot to bring the Numeric and Named fields into separate rows:

Then after the pivot, we need to retain a row for each HTML code and Char, so we can use an aggregation field to group these:
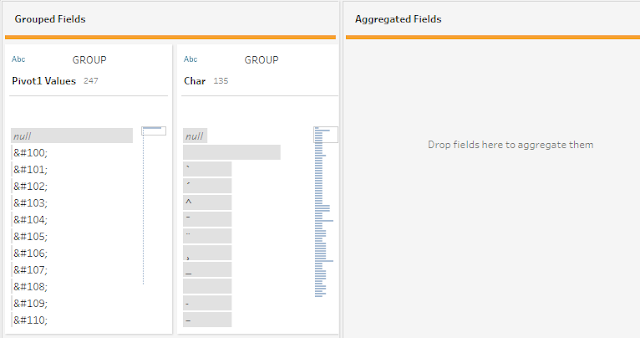
After the aggregation and renaming the fields, our HTML table should look like this:

Step 3 - Replace HTML
We are now in a position to start replacing the HTML code with the correct characters. Within the requirements we are told that the HTML code starts with a '&' and ends with a ',', therefore we need to use this to extract the parts from the movie title.
We can extract these using Regex_Extract_Nth function, this will be repeated 5 times depending on how many times the HTML code appears in the movie title:
html1
REGEXP_EXTRACT_NTH([Movie],'(&[\w#]+;)',1)
html2
REGEXP_EXTRACT_NTH([Movie],'(&[\w#]+;)',2)
html3
REGEXP_EXTRACT_NTH([Movie],'(&[\w#]+;)',3)
html4
REGEXP_EXTRACT_NTH([Movie],'(&[\w#]+;)',4)
html5
REGEXP_EXTRACT_NTH([Movie],'(&[\w#]+;)',5)

The next step is to replace the isolated HTML code with the correct characters from the lookup table. This involves joining the table onto each of the split HTML fields. Again, this will need to be repeated 5 times!
Join 1 - html1 = html

Join 2 - html2 = html

Join 3 - html3 = html

Join 4 - html4 = html

Join 5 - html5 = html
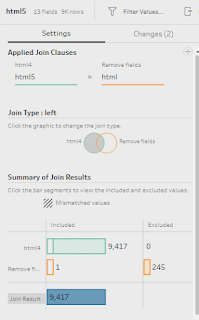

Then finally we can use a calculation to replace the HTML code with the correct character in each Movie Title. Again, we need to repeat this 5 times with a similar calculation:
Movie
IF NOT ISNULL([html1])
THEN REPLACE([Movie],[html1],[Char1])
ELSE [Movie]
END
Movie
IF NOT ISNULL([html2])
THEN REPLACE([Movie],[html2],[Char2])
ELSE [Movie]
END
Movie
IF NOT ISNULL([html3])
THEN REPLACE([Movie],[html3],[Char3])
ELSE [Movie]
END
Movie
IF NOT ISNULL([html4])
THEN REPLACE([Movie],[html4],[Char4])
ELSE [Movie]
END
Movie
IF NOT ISNULL([html5])
THEN REPLACE([Movie],[html5],[Char5])
ELSE [Movie]
END
After these calculations we should now have a clean movie list title with all the correct characters:

Step 4 - Parse Test Outcome
We can now turn our attention to the outcome of the test, and parse that from the HTML string.
First we want to split the DownloadData Split 2 field by using the '[' as a separator:

We are then left with multiple fields, and we want to remove all apart from DownloadData - Split 2 - Split 4 (this contains the reason for pass/fail), DownloadData - Split 2 - Split 1 (this contains the pass/fail result), Movie, and Year.
From here we can split the DownloadData - Split 2 - Split 4 again, but this time only splitting off the first occurrence before the ']', which leaves us with the following categorisations:

Then finally, we can complete the parsing by using an automatic split on the DownloadData - Split 2 - Split 1 field, which will leave us with nopass and pass. Here we can just rename both of these values to Pass and Fail.
Our table should now look like this:

Step 5 - Rank Categorisations
Next, we need to rank each of the categorisations from 1 to 5. To do this, we first need to ensure that no movies are repeated on multiple rows, so we can use an aggregation tool to group all of the different movies, years etc:

Then from here we can rank the categories from 1 to 5. First we need to duplicate the Categorisation field and then using the grouping functionality we can rename the fields to the following:
- There are two or more women in this movie and they talk to each other about something other than a man
- There are two or more women in this movie and they talk to each other about something other than a man, although dubious
- There are two or more women in this movie, but they only talk to each other about a man
- There are two or more women in this movie, but they don't talk to each other
- Fewer than two women in this movie

Step 6 - Remove Duplicates
The final step is to remove any movies that appear multiple times, and to keep only the worse ranking.
First, we need to identify the movies that are duplicated. We can do this by using a FIXED LOD:

Then we want to filter to keeping only the multiple values (2 or more) and then use an aggregation tool to find the Max ranking for each Movie and Year combination.

Now we can join these back onto our original data set, with an inner join on Ranking, Movie, and Year:

Notice how this only keeps the 6 rows that have multiple films, therefore we need to go back and create a new branch so that we can filter the Number of Rankings to 1 as well.
Once filtered, we can union this back to our workflow so that we have a total list of all the movies.
After the union, we are ready to output our data that should look like this:

You can download the full output here.
After you finish the challenge make sure to fill in the participation tracker, then share your solution on Twitter using #PreppinData and tagging @Datajedininja, @JennyMartinDS14 & @TomProwse1
You can also post your solution on the Tableau Forum where we have a Preppin' Data community page. Post your solutions and ask questions if you need any help!


