2023: Week 26 - Prep School 2023 Admissions - Part 2
Challenge by: Ross Killington
This is our next challenge from one of the members of the 38th cohort of the Data School UK, and it's a follow on from last week!
After last week's challenge we now have a useful table populated with 4,000 students applying to the Prep School with their respective grades and total scores. This week however it’s crunch time, we need to decide which students will be accepted into the school for the new academic year.
We are supplied with some new data relating to the students including which course they want to study, as well as details about their address and proximity to the school.
Prep School offers 5 courses:
- Business Management
- Computer Science
- Psychology
- Engineering
- Data Analytics
Each course can take 20 students, usually it would be a half and half split between students from each region but this year due to a population imbalance we have been asked to accept a split of 75% East Students and 25% West Students on each course.
To make our selections, we first treat our applicants as 5 different groups depending on which course they’re applying to and then we look at their grade score, taking on the students with the highest grade score for each subject selection. When students are tied on the same grade score we then refer to their proximity to the school to separate them, with the closest students being accepted.
Finally, once we have our list of accepted students, we like to note whether the students are from a high, average or low performing secondary school, based on the acceptance rate into the Prep School.
Inputs
We have 2 inputs this week:
1. Our output from last week - don’t worry if you didn’t take part in last week’s challenge as the output data is supplied for you: “Part 1 Output.csv"
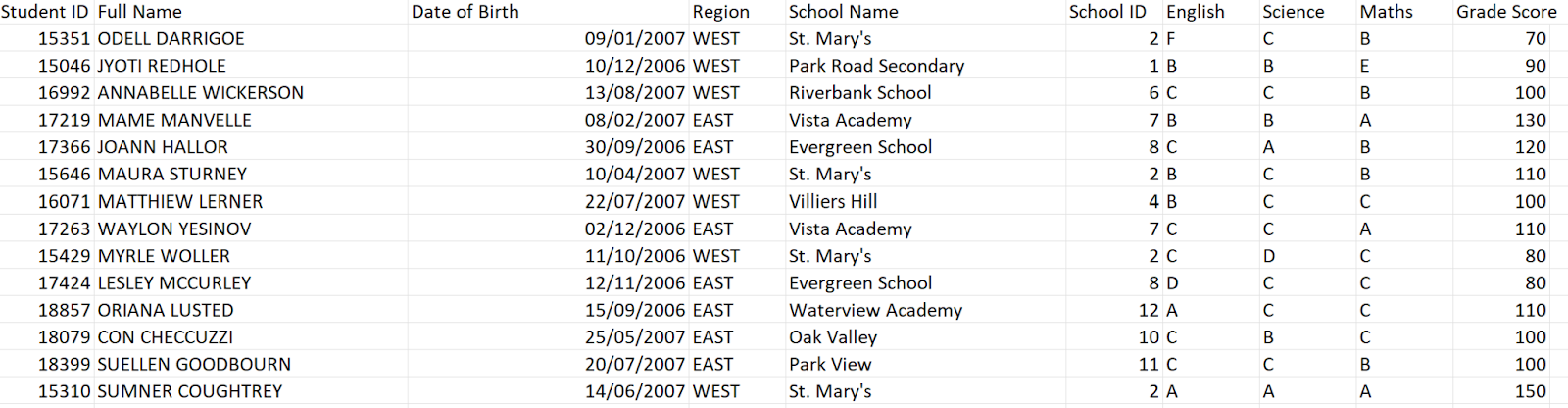
2. Our table of additional information needed to make the decision: “Additional Info Lookup.csv”

Requirements
- Input the data
- Create a new column in the Part 1 Output table for each student’s initials. If a student has a double barreled second name then only take the first letter from the first part
- e.g. “NERTY CHERRY HOLME” becomes NC not NCH.
- Find a way to join this table to the Additional Information table. We should maintain exactly 4,000 unique records.
- Develop a ranking system to rank each student by Grade Score within their specified Subject Selection and Region. Every combination of Subject Selection and Region should have their own ranking and remember that if students have a matching grade score, we then prioritise those who live closer to the school as a “tie-breaker”.
- For each Subject, find and flag the top 20 students with the caveat that this year within each course, 15 students must be from the East and 5 from the West given our newly imposed 75%/25% split
- Delete all rejected students, leaving only the 100 accepted students.
- Remove unnecessary fields
- Find the total number of accepted applicants per secondary school and represent this as a percentage of the total spaces that were available for that region.
- Hint: think about how many were allowed per course, and how many courses there are
- For each region, label their highest performing school as “High Performing” and the lowest performing school as “Low Performing” in a new column named “School Status”.
- Give all other schools the status “Average Performing”
- Delete any unwanted fields and rearrange to give the output shown below
- Output the data
Output

- 11 fields
- Student ID
- Full Name
- Date of Birth
- Region
- School Name
- School Status
- Subject Selection
- English
- Maths
- Science
- Grade Score
- 100 rows (101 including headers)


